Letzte Woche Freitag stolpert der unabhängige Entwickler Pieter Levels im LM Arena über drei eigenartige Modellnamen: maskingtape-alpha, gaffertape-alpha, packingtape-alpha. Klingt nach dem Lagerregal eines Baumarkts. Ist aber mit hoher Wahrscheinlichkeit OpenAIs nächste Generation der Bildgenerierung — intern als Image V2 geführt, von der Community bereits GPT-Image-2 genannt.
Die Reaktion: sofortiger Hype, hunderte Community-Tests innerhalb von Stunden, Vergleichsbilder auf X und Reddit. OpenAI hat das Ganze weder bestätigt noch dementiert. Die Models wurden über das Wochenende aus dem Arena entfernt — tauchen aber weiterhin sporadisch in ChatGPT auf, wo sie über ein A/B-Test-Framework an ausgewählte Plus- und Pro-User ausgespielt werden.
Warum das kein gewöhnlicher Leak ist
OpenAI nutzt das LM Arena schon länger als stille Testumgebung, bevor neue Modelle offiziell ankommen. Im Dezember 2025 tauchten dort zwei Bildmodelle unter den Codenamen Chestnut und Hazelnut auf — wenige Wochen später erschien GPT-Image-1.5. Dieselbe Playbook, dieselbe Methodik.
Der entscheidende Unterschied diesmal: GPT-Image-2 ist keine inkrementelle Verbesserung. Mehrere Quellen und Community-Tests beschreiben eine von Grund auf neue Architektur — kein Finetuning auf Basis von GPT-4o, sondern ein dediziertes Bildgenerierungsmodell. Das ist relevant, weil es bedeutet: andere Kostenstruktur, andere API-Endpunkte, andere Grenzen als das, was bisher bekannt ist.
Was die Tester berichten
Pieter Levels war der erste, der die Modelle öffentlich benannte — und sein Fazit war knapp: “unglaubliches Weltwissen, exzellentes Textrendering.” Die Community hat seitdem systematisch nachgetestet. Hier die wichtigsten Erkenntnisse:
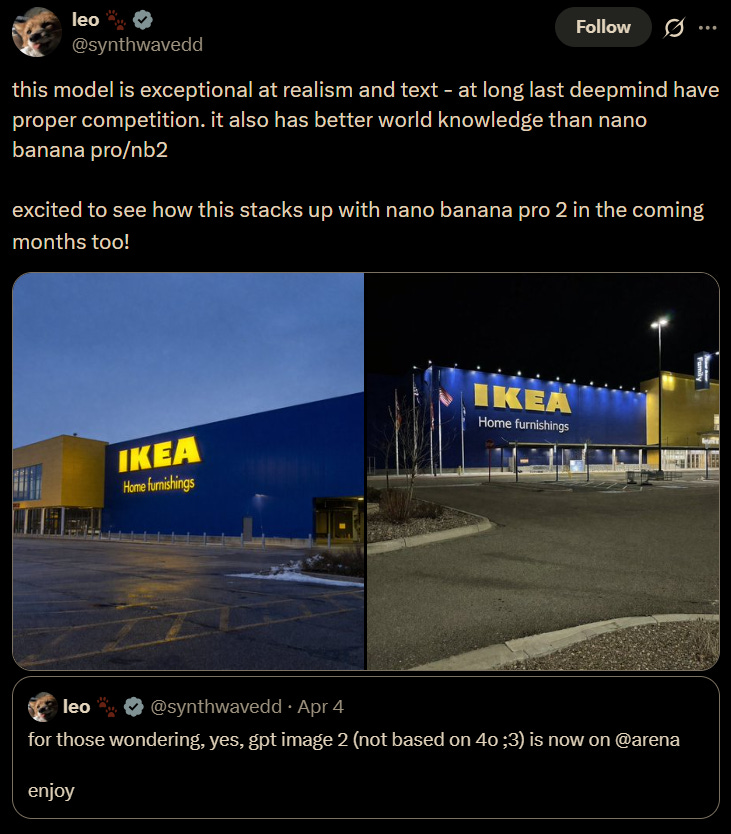
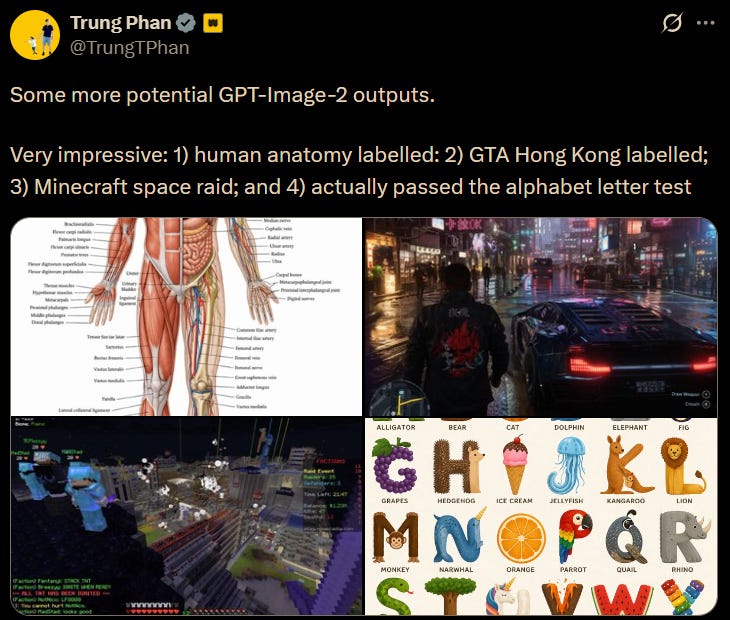
Textrendering, endlich brauchbar. Das war über Jahre die Achillesferse aller Bildgeneratoren. GPT-Image-1.5 hat bereits solide Fortschritte gemacht, aber bei dichten Layouts, langen Texten oder UI-Elementen gab es regelmäßig Buchstabensuppen. GPT-Image-2 soll laut Tests 99 %+ Textgenauigkeit liefern — klare, scharfe Typografie, auch in komplexen Kompositionen wie Poster oder App-Screenshots.
Weltwissen in Bildern. Ein Test, der die Community besonders beschäftigt hat: Uhren. Das Modell soll bei der Anfrage nach einer bestimmten Markenuhr die korrekte Zeit korrekt darstellen — Zeiger an der richtigen Position, authentische Details. Googles aktuell führendes Modell scheiterte an demselben Test. Klingt nach einem Nischenfall, ist aber ein Indikator für etwas Grundlegenderes: das Modell versteht Kontext, nicht nur Pixel.
Photorealismus auf neuem Niveau. Community-Feedback auf X und Reddit ist selten so einheitlich: “Makes the competition look like DALL-E.” Texturen, Licht, Materialoberflächen — Tester beschreiben eine Qualität, bei der die Grenze zur Fotografie zunehmend schwer zu ziehen ist.
Spatial Reasoning — noch nicht gelöst. Der klassische Rubik’s-Cube-Spiegeltest scheitert das Modell noch. Das ist kein OpenAI-spezifisches Problem, sondern zeigt, wo die gesamte Branche noch Nachholbedarf hat. Komplexe dreidimensionale Logik in Bildern ist weiterhin ein offenes Problem.
Der Wettbewerbskontext
OpenAI steckt seit Ende 2025 in einer ungewohnten Verteidigungsposition. Googles Nano Banana Pro hat sich auf dem LM Arena Leaderboard an die Spitze gesetzt — und OpenAI kämpft darum, diesen Platz zurückzugewinnen. Sam Altman sprach intern von einem “Code Red”-Modus.
In direkten Arena-Blindvergleichen soll GPT-Image-2 Nano Banana Pro in zentralen Kategorien schlagen: Textgenauigkeit, UI-Rekonstruktion, Weltwissen. Bei Midjourney V7 liegt der Vorteil im Bereich Photorealismus und vor allem Textrendering — Midjourney ist nach wie vor stark bei künstlerischen Stilen, aber bei realistischen Kompositionen mit Text verliert es deutlich. Gegenüber FLUX liegt der Unterschied vor allem im Weltwissen und in der Konsistenz komplexer Szenen.
| Vergleich | GPT-Image-2 Stärke | Schwäche |
|---|---|---|
| vs. Nano Banana Pro | Text, Weltwissen, UI | Noch ungetestete Edge Cases |
| vs. Midjourney V7 | Photorealismus, Textrendering | Künstlerische Stilvielfalt |
| vs. FLUX Pro | Weltwissen, komplexe Szenen | Open-Source-Flexibilität |
| vs. Ideogram 3.0 | Breitere Capability | Spezialisierung |
Warum jetzt — der Sora-Faktor
Am 24. März 2026 hat OpenAI Sora eingestellt. Das Videogenerierungsmodell hat seine wirtschaftlichen Ziele klar verfehlt: laut Forbes täglich bis zu 15 Millionen Dollar Inferenzkosten bei einem Lifetime-Revenue von 2,1 Millionen Dollar. Der Nutzer-Peak lag bei einer Million, dann fiel er auf unter 500.000.
Die freigegwordenen GPU-Ressourcen müssen irgendwo hin. Dass GPT-Image-2 jetzt in dieser Geschwindigkeit in die Arena und ins ChatGPT-Testing geht, ist kein Zufall.
Was das für Teams und Entwickler bedeutet
Wer heute auf GPT-image-1.5 via API baut, sollte sich auf einen Modellwechsel vorbereiten. Die neue Architektur bedeutet wahrscheinlich andere API-Parameter, möglicherweise höhere Kosten pro Bild (geschätzt 0,15–0,20 Dollar pro High-Quality-Output statt aktuell 0,133 Dollar), aber auch deutlich bessere Ergebnisse bei den Anwendungsfällen, die bisher am meisten Nacharbeit erfordert haben: UI-Mockups, Produktfotos mit Text, Infografiken, Marketingmaterial.
Die Community-Theorie ist, dass ChatGPT Plus- und Pro-User über komplexe Prompts — viel Text, Interface-Elemente, Produktshots — die Wahrscheinlichkeit erhöhen können, GPT-Image-2 zu triggern. Wer den Vergleich selbst machen will: 16:9-Format im Prompt anfordern. Wenn das klappt und der Output gestochen scharf ist ohne den warmen Gelbstich von GPT-Image-1.5, dann läuft gerade die neue Version.
Fazit
GPT-Image-2 ist real, es ist gut, und es kommt bald. Die Arena-Daten, das A/B-Testing in ChatGPT und OpenAIs historische Release-Zyklen deuten auf ein offizielles Launch-Fenster im April oder Mai 2026 hin. Für Entwickler und Teams, die Bildgenerierung produktiv einsetzen, ist das ein direkter Handlungsimpuls: Workflows dokumentieren, API-Integrationen vorbereiten, Testing-Budgets einplanen.
Wer dabei Unterstützung beim Aufbau von AI-gestützten Workflows oder der Integration neuer Modelle in bestehende Systeme braucht — sprich uns an. Wir beobachten diese Entwicklungen nicht nur, wir bauen damit.